Shap 라이브러리에는 SHAP 값을 시각화하는 멋진 도구가 있습니다. 폭포 플롯은 개별 특징 벡터에 대한 SHAP 값을 표시할 수 있습니다. 예를 들어 Boston 데이터 세트에서 XGBoost 모델을 학습하고 X의 한 인스턴스에 대한 폭포 플롯을 표시합니다.
d = load_boston()
df = pd.DataFrame(d['data'], columns=d['feature_names'])
X = df
y = pd.Series(d['target'])xgb_model = xgboost.XGBRegressor(random_state=1).fit(X, y)explainer = shap.Explainer(xgb_model, X)
explanation_object = explainer(X)
shap_values = explainer.shap_values(X)# visualize the first prediction's explanation
shap.plots.waterfall(explanation_object[0])

폭포 플랏은 다음 식에 의해 그려집니다.

워터폴 플롯은 이 방정식을 시각화할 수 있습니다. 워터폴 플롯의 하단은 E[f(x)]=22.343에서 시작하고 이 플롯의 각 화살표는 예측에 대한 각 기능의 양수(빨간색) 또는 음수(파란색) 기여도를 보여줍니다. 각 화살표의 길이는 해당 기능의 절대 SHAP 값과 같습니다. SHAP 값은 화살표 위에 쓰여지고 해당 기능의 값도 세로 축에 쓰여집니다(예를 들어 위의 플롯에서 기능 LSTAT의 값은 4.98이고 해당 SHAP 값은 4.64입니다). SHAP 값이 양수이면 화살표가 빨간색이고 오른쪽으로 이동합니다. 음수 SHAP 값의 경우 파란색이고 왼쪽으로 이동합니다. 이 화살표를 따라가면 마침내 모델 예측 값 f(x)=21.019에 도달합니다. 피처는 SHAP 값의 절대값을 기준으로 정렬되므로 절대 SHAP 값이 가장 큰 피처가 맨 위에 놓입니다. Explainer의 shap_values() 메서드에서 반환된 SHAP 값이 아니라 Explainer 개체를 waterfall()에 직접 전달해야 합니다.
힘 플롯을 사용하여 SHAP 값을 시각화할 수도 있습니다.
shap.initjs()
shap.plots.force(explanation_object[0])

힘 플롯은 폭포 플롯과 유사하지만 화살표가 수평으로 쌓입니다. 빨간색과 화살표는 길이에 따라 정렬되므로 빨간색 화살표는 왼쪽에서 오른쪽으로 갈수록 길어지고 파란색 화살표는 오른쪽에서 왼쪽으로 길어집니다. 각 기능의 값(SHAP 값이 아님)은 해당 화살표 뒤에 표시됩니다. 가장 긴 빨간색과 파란색 화살표는 f(x)=21.019에서 교차합니다. E[f(x)]=22.343의 값은 기본 값으로 표시된 플롯에도 표시됩니다.
막대 그래프를 사용하여 SHAP 값을 표시할 수도 있습니다. 우리는 Explanation 객체를 취하는 shap.plots.bar() 함수를 사용할 수 있습니다. 막대 그래프에는 화살표, f(x) 및 E[f(x)] 값, 기능 값이 표시되지 않습니다. 각 막대의 길이는 해당 기능의 절대 SHAP 값과 같습니다. 막대는 양수/음수 SHAP 값에 대해 빨간색/파란색으로 표시되며 SHAP 값은 각 막대 옆에 기록됩니다. 기능은 SHAP 값의 절대값을 기준으로 정렬됩니다.
shap.plots.bar(explanation_object[0])

막대 그래프가 절대 SHAP 값만 표시하도록 강제할 수도 있습니다.
shap.plots.bar(explanation_object[0].abs)

beeswarm 플롯은 많은 인스턴스에 대한 SHAP 분석을 요약하는 데 유용합니다. 먼저 하나의 인스턴스에만 사용합니다. shap.plots.beeswarm() 함수는 설명 개체를 사용합니다. 이 함수에는 버그가 있고 호출하면 가져오는 Explanation 개체의 SHAP 값이 변경되므로 항상 Explain 개체의 전체 복사본을 전달해야 합니다.
import copy
shap.plots.beeswarm(copy.deepcopy(explanation_object[0:1]))
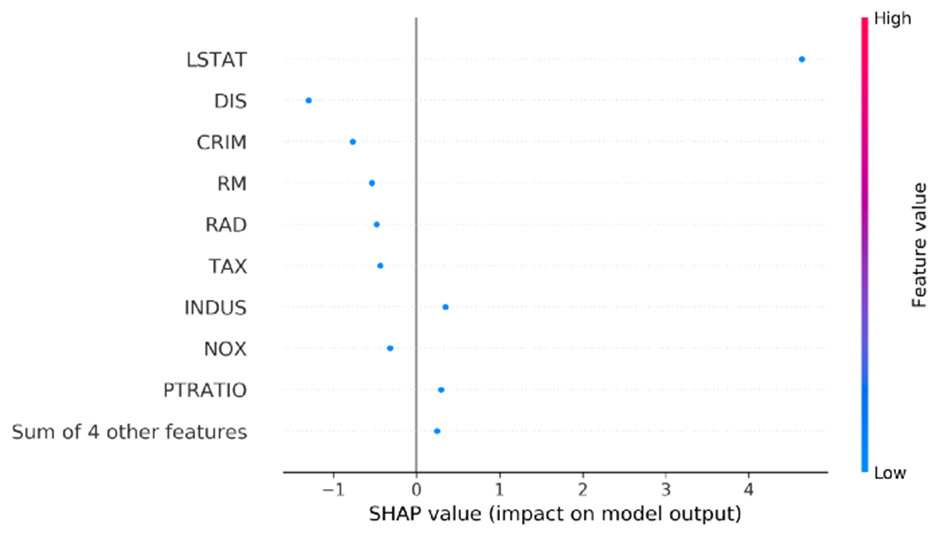
플롯은 막대 플롯과 유사하지만 막대 대신 각 SHAP 값에 대한 점이 있습니다. 각 점의 x 위치는 해당 기능의 SHAP 값을 제공합니다. 인스턴스가 하나뿐이므로 모든 점의 색상이 동일합니다. 이제 두 가지 인스턴스에 대해 시도합니다. 이제 각 기능에 대해 두 개의 점이 있고 각 점은 인스턴스 중 하나를 나타냅니다.
shap.plots.beeswarm(copy.deepcopy(explanation_object[0:2]))
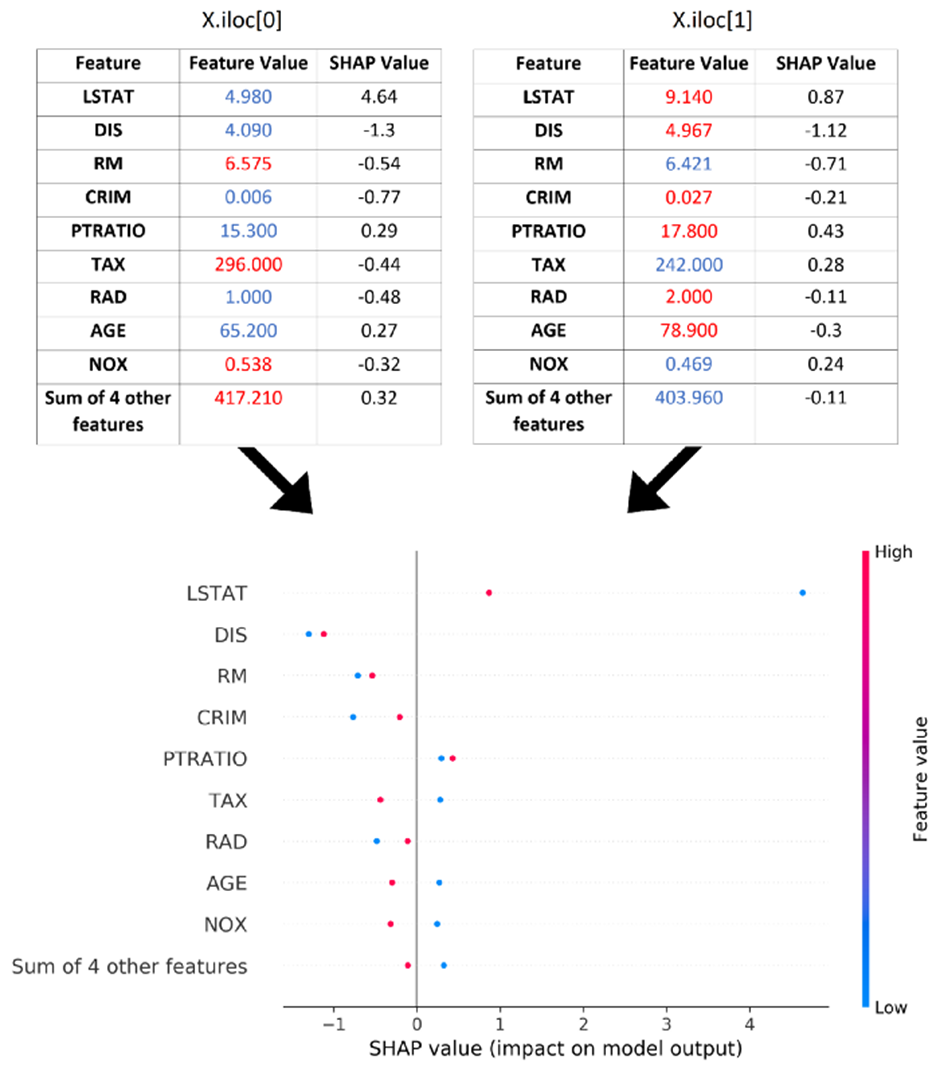
점은 해당 기능의 값에 따라 색상이 지정됩니다. 각 기능에 대해 (해당 기능의) 값이 더 높은 인스턴스는 빨간색이고 다른 인스턴스는 파란색입니다. 그러나 인스턴스가 둘 이상인 경우 기능이 어떻게 정렬됩니까? 기능은 모든 인스턴스의 절대 SHAP 값의 평균을 기준으로 정렬됩니다. 이제 더 많은 인스턴스에서 시도해 볼 수 있습니다.
shap.plots.beeswarm(copy.deepcopy(explanation_object))
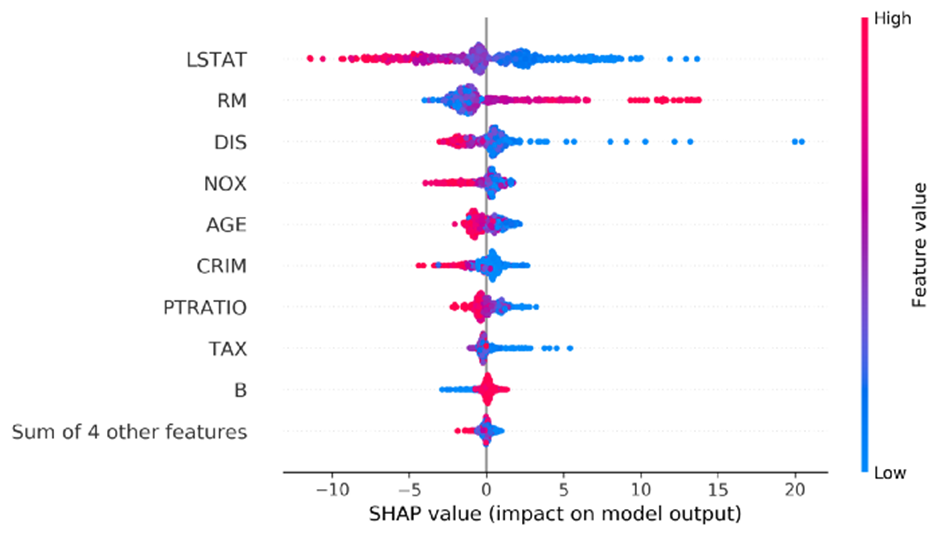
이 플롯에서 최대 SHAP 값은 기능 DIS에 속하지만 LSTAT는 모든 인스턴스에 대해 가장 높은 평균을 갖습니다. 이를 변경하고 최대 절대 SHAP 값으로 기능을 정렬할 수 있습니다.
shap.plots.beeswarm(copy.deepcopy(explanation_object), order=explanation_object.abs.max(0))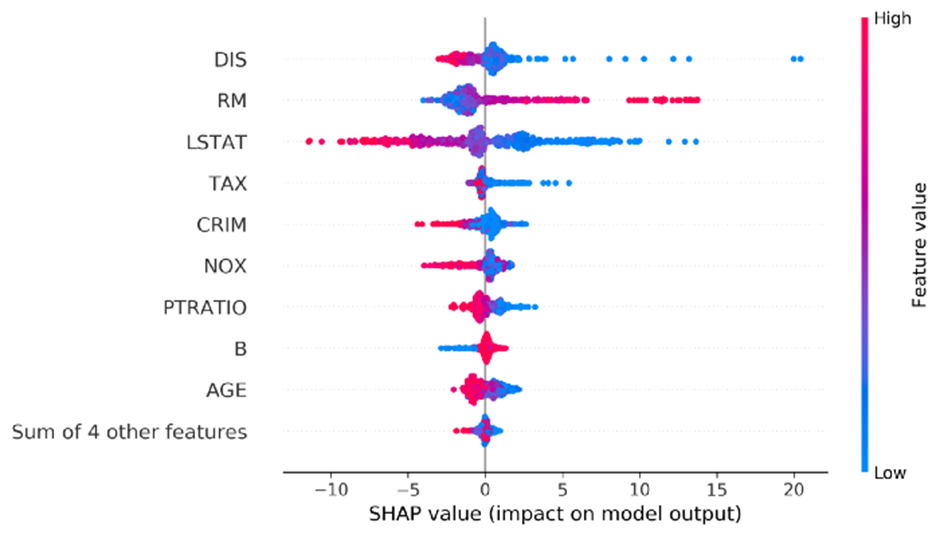
이제 DIS가 정상에 올랐습니다. 막대 그래프와 함께 둘 이상의 인스턴스를 사용할 수도 있습니다. 이 경우 모든 인스턴스의 절대 SHAP 값의 평균을 계산하고 이를 기준으로 기능을 정렬합니다. 절대 SHAP 값의 평균도 막대 옆에 표시됩니다.
shap.plots.bar(explanation_object)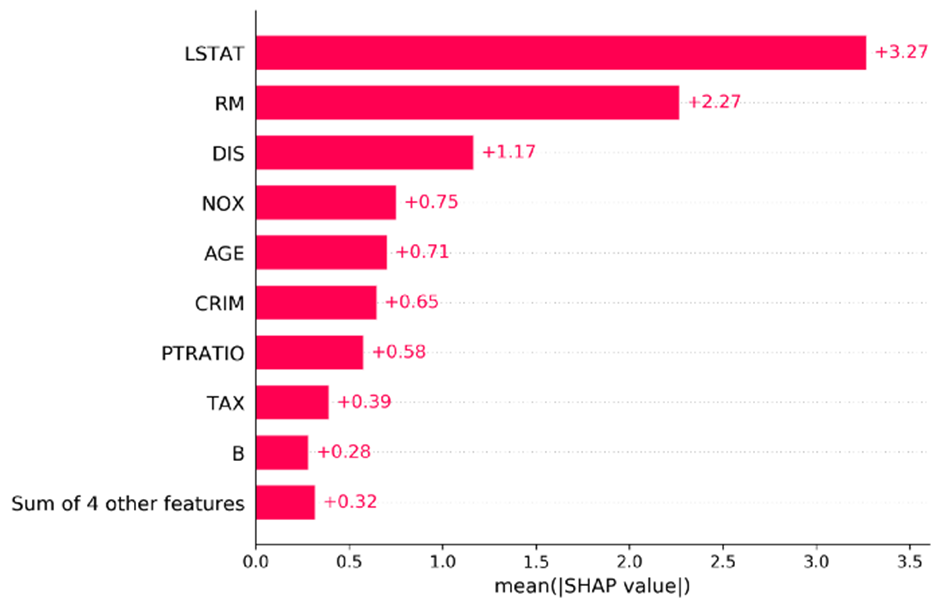
마지막으로 여러 인스턴스에 대한 힘 플롯을 표시할 수 있습니다. 다음은 3가지 인스턴스에 대한 예입니다.
shap.force_plot(explainer.expected_value, shap_values[0:3,:], X.iloc[0:3,:], plot_cmap="DrDb")
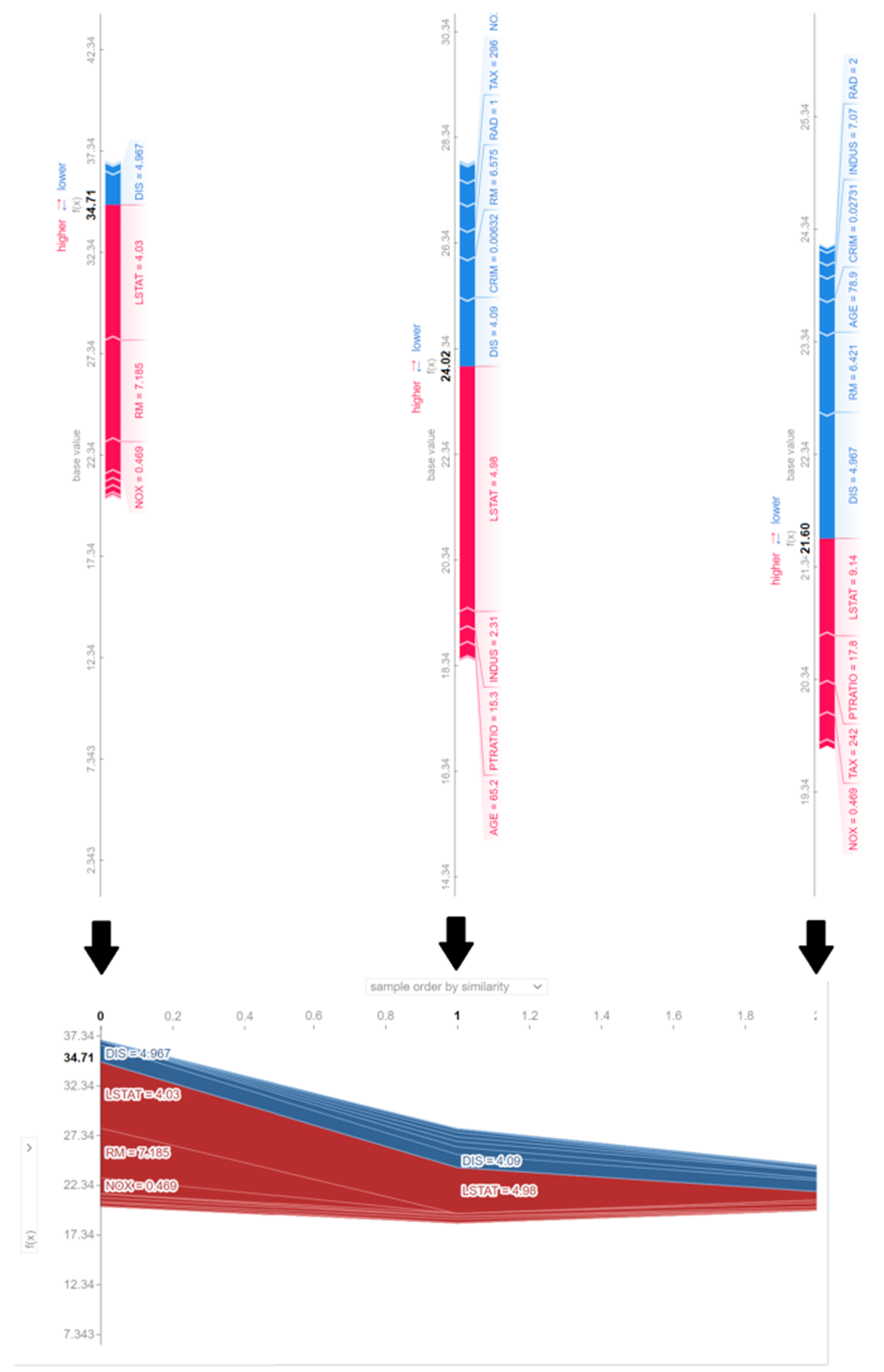
이 플롯은 90도 회전되고 수평으로 쌓인 3개의 개별 힘 플롯의 조합입니다. 더 많은 인스턴스가 있는 또 다른 예는 다음과 같습니다.
shap.force_plot(explainer.expected_value, shap_values, X,
plot_cmap="DrDb")
shap.force_plot(explainer.expected_value, shap_values, X, plot_cmap="DrDb")
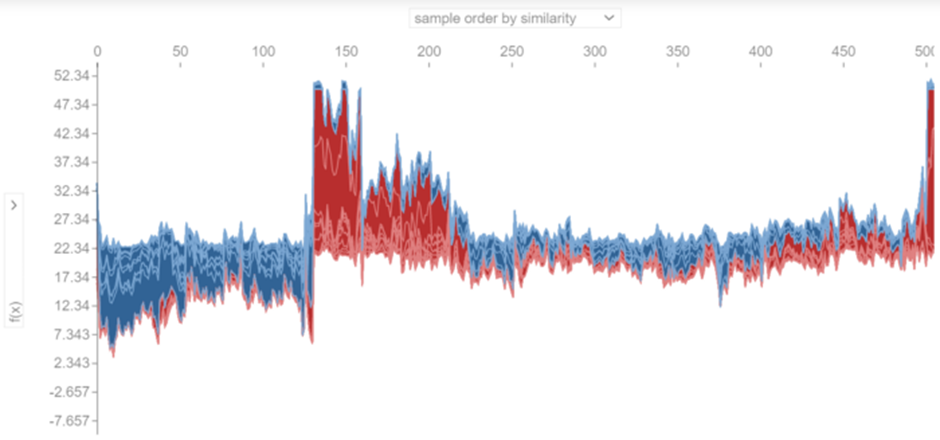
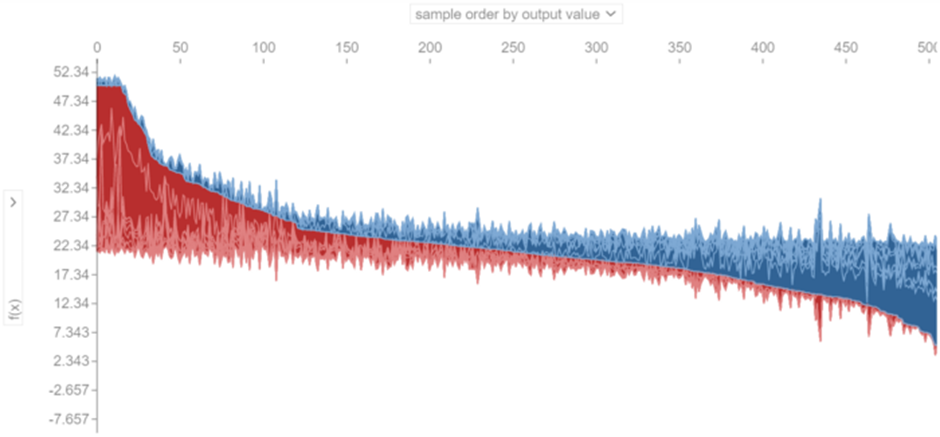
개별 힘 플롯이 쌓이는 방식을 선택할 수 있습니다. 예를 들어, 그림 25에서 개별 플롯은 유사성을 기반으로 누적됩니다. 각 인스턴스의 SHAP 값이 M차원 공간에서 점을 형성한다고 가정하면 유사성은 이 점 사이의 유클리드 거리에 의해 결정되며 더 유사한(더 작은 거리를 갖는) 점(또는 인스턴스)은 함께 쌓입니다. 인스턴스를 쌓을 수 있는 몇 가지 다른 옵션이 있습니다. 예를 들어 각 인스턴스에 대해 f(x) 값을 기준으로 정렬할 수 있습니다. 이는 그림 26에 나와 있습니다. 여기서 인스턴스에 대한 f(x) 값은 왼쪽에서 오른쪽으로 감소합니다.
기계 학습 모델을 설명하는 것은 중요한 주제입니다. 설명한다는 것은 모델의 개별 예측과 해당 예측을 생성하는 데 사용되는 기능 간의 관계를 질적으로 이해하고 싶다는 의미입니다. 간단하고 해석 가능한 모델 설명자를 사용하여 복잡한 모델을 설명하고 기능 중요도를 결정할 수 있습니다. SHAP는 Shapley values라는 게임 이론 개념을 기반으로 개발된 개별화된 모델 불가지론적 설명자입니다. SHAP 값은 원칙적으로 모든 기계 학습 모델을 설명할 수 있는 선형 모델의 계수를 제공합니다.
SHAP 값에는 몇 가지 바람직한 이론적 속성이 있지만 실제로 정확한 SHAP 값을 계산하는 것은 계산 비용이 많이 들기 때문에 커널 SHAP와 같은 몇 가지 방법을 사용하여 SHAP 값을 근사화합니다. 이 기사에서는 먼저 Shapley 값의 수학적 개념과 기계 학습 모델을 설명하는 데 사용할 수 있는 방법을 설명했습니다. 또한 SHAP 값과 이를 추정하는 데 사용할 수 있는 다양한 알고리즘에 대해서도 논의했습니다. 이 모든 알고리즘은 처음부터 Pythom에서 구현되었습니다. 마지막으로 Python의 SHAP 라이브러리와 SHAP 값을 시각화하기 위해 제공하는 플로팅 도구에 대해 논의했습니다.
이 기사를 읽으셨기를 바랍니다. 질문이나 제안 사항이 있으면 알려주세요. 이 기사의 모든 코드 목록은 https://github.com/reza-bagheri/SHAP의 GitHub에서 Jupyter 노트북으로 다운로드할 수 있습니다.
'Data Analysis' 카테고리의 다른 글
| 설명가능한 인공지능(XAI) 관련 설명(2) (0) | 2023.01.16 |
|---|---|
| 설명가능한 인공지능(XAI) 관련 설명(1) (0) | 2023.01.15 |
| [ML] SHAP의 수학적 설명 (0) | 2023.01.14 |
| [ML] Shapley Value의 머신러닝 적용 (0) | 2023.01.13 |
| [ML] SHAP 소개 (3) | 2023.01.13 |


댓글